



.jpg)
.png)
.jpg)


Dependencies:
- Solr 7.5
- Cassandra 3.11.3
- Node v10.13.0
- Restify 7.2.2
- TypeScript 3.1.6
What is Solr?
Solr is a powerful search platform built on Lucene. Similar in nature to the more popular ElasticSearch, Solr focuses on text search whereas ElasticSearch provides more analytics capabilities.
Features include:
- Full-text search
- Highlighting
- Faceted search
- Real-time indexing
- Dynamic clustering
- Database integration
- XML, JSON, and HTTP support
- NoSQL features and rich document handling (Word and PDF files, for example)
Here is an actively maintained analysis on ElasticSearch vs Solr.
My Overall Architecture
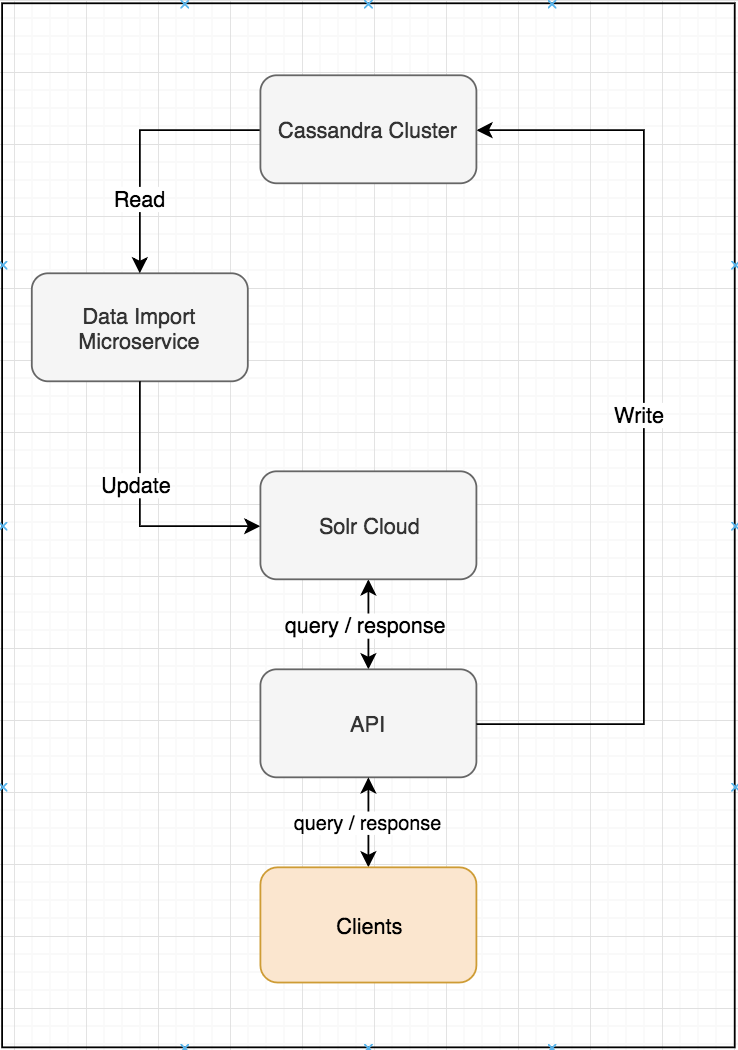
In this app, the API reads and queries Solr while writing to Cassandra. A separate Data Import service was created to continuously update the indexes in Solr.
The Data Import Service should regularly ping Cassandra using a delta import query after the initial full import, preferably after each write to Cassandra.
Setting up your API with RESTIFY
First, let’s bootstrap a TypeScript project. Get TypeScript if you don’t already have it.
npm i typescript@3.1.6 — save-dev
Init a simple project with tsc — init. I also recommend using Google’s style in tsconfig. You can use their hassle-free setup with this project.
Next, get Restify and the CORS middleware
npm i restify@7.2.2 restify-cors-middleware
Then, make a file called api.ts and put the following content in there. I will explain each section.
The CORS set up is standard from what you expect from a services with CORs setup. There’s the preflight request, the sanitization of parameters, body parsing, etc. If your service requires more nuanced features, feel free to look at the repo for guidance.
The next bit of code with the initializeControllers reads from src/controller directory and loads each subdirectory. You can easily customize the logic here to your liking, but I found this configuration to be pretty handy.
Note, that we also need to declare a simple settings for the app.
Below is an example of a controller. It’s just a health endpoint that returns a 200 when you call it.
Every controller in Restify requires a function that intakes the 3 arguments shown above, typed to provide clarity. (You might need to install the respective typings as well if you want Intellisense). Eg, npm i @types/restify --save-dev
This exports the controller method we declared earlier to the corresponding verb and route. Line 46 in api.ts loads the routes from each route.
You’re now ready to test if the Restify service works. Here’s my npm script that I use to boot up to clean the build dir, compile, and then start up the server. gts comes from the Google TypeScript. It simply removes everything in the build dir.
"start": "npm run clean && npm run compile && node ./build/src/api.js"
"clean": "gts clean"
"compile": "tsc -p ."
Sending a GET request to localhost:3000/health should give you a 200.
$ curl -i -X GET localhost:3000/healthHTTP/1.1 200 OK
Server: typescript-seed
Content-Type: application/json
Content-Length: 11
Connection: Keep-Alive
Content-MD5: Hl9aqSbxcxGVdyLGWa8ASQ==
Date: Tue, 14 Nov 2018 15:04:02 GMT
Request-Id: 4a099ca7–7341–4136-a78a-a63ef7573d87
Response-Time: 1
"beep boop"
Setting up Cassandra
Let’s continue with getting a Cassandra instance up, connecting to it, and seed some data to it.
You need Java 8 when you do java -version. Use this if you need help getting a specific Java version on Mac.
brew install cassandra
brew services start cassandra
Cassandra should now be started on port 9042. You can now play around with your instance with cqlsh. Read more on the things you can do here.
Run this command in cqlsh to make a keyspace. I called mine cassandrasolr. To learn more about keyspaces, read this.
CREATEKEYSPACE cassandrasolr
WITHREPLICATION = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};
Let’s now connect to Cassandra in our API so we can make it execute queries.
Get Datastax’s NodeJS driver with npm install cassandra-driver --saveGetting the types can also be helpful npm i @types/cassandra-drive --save-dev .
Create a new file called cassandra-client.ts to house our new CassandraClient class that we’re going to instantiate on app start and fire off requests from.
In this file, I hardcode the host and port (‘127.0.0.1:9042’) and keyspace (‘cassandrasolr’). It might be prudent for you to move them to a editable config file (same as config.ts).
The interesting stuff is the seedData function that basically seeds the data for you on app start. I create the table if it doesn’t exist, and insert each Object into Cassandra using this.client.execute . You do not need to use Batch query as in Cassandra, Batch does not improve speed but ensures atomicity (either everything is OK or nobody gets through)
Now, when you restart your server, data should be seeded to Cassandra accordingly. You may confirm it with a query on cqlsh , eg SELECT * FROM PEOPLE;
Setting up Solr
Get Solr with homebrew brew install solr(if it doesn’t get 7.5, you might need to do brew install solr@7.5).
You can just boot up Solr Cloud with their example configuration for now solr -e cloud .
Create your Solr collection in the CLI with solr create -c mycollection .
You can navigate to localhost:8983 and access the Solr Admin console. There isn’t any data in your collection, but we’re going to update your indexes now with the pieces we’ve set up.
Importing Service
For the purpose of this quick demo, I’ll reuse the API app. In the future, I would segregate this functionality and use Cassandra’s built-in triggers to decide when to fire a partial import query. For now I’ll just fire once with a full import of the records in Cassandra.
Here is my ImportController:
I brought in Axios to fire some HTTP requests. Feel free to use whatever HTTP library you’d like. In this endpoint, I fetch the Cassandra data and simply send them over to the /update endpoint of Solr. Make sure the commit parameter is set to true.
A 200 is returned if the update was successful. Else, a 400 would be returned with the error message. One thing that I would like to have done is to have the solrRes from a successful Solr update to have more info. For example, how many records were successful, and if failed, how many and which one failed the import.
You should now be able to directly query your Solr instance using HTTP.
$ curl -i -g http://localhost:8983/solr/mycollection2/select?q=age:[*%20TO%2019]HTTP/1.1 200 OK
Content-Type: application/json;charset=utf-8
Content-Length: 3777{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"age:[* TO 19]"}},
"response":{"numFound":293,"start":0,"docs":[
{
"id":"f9409895-261e-4112-bac8-b6baf6faf298",
"age":[19],
"balance":["$3,824.64"],
"email":["ursulathomas@eclipsent.com"],
"eyecolor":["blue"],
"gender":["female"],
"isactive":[true],
"name":"Ursula Thomas",
"phone":["+1 (892) 543-2675"],
"_version_":1617591717901369344},
{
"id":"8794f173-a438-45b7-8331-85a654941702",
...
Completing the endpoint
With all the parts set up, we can finally build the endpoint that searches for People.
I took a quick and dirty approach here by allowing the client to pass in query params, but filter it with the buildQuery method and convert the query param into a Solr query.
This allows some sort of control as to what can be exposed. I would recommend a more scalable approach going forward than littering the app with buildQuery functions. Perhaps a single file that maps all the allowed fields per resource.
To investigate
There is so much to go from here on. Here’s a running list of stuff I came upon while working on this tutorial.
- Automatically reload and restart the server upon saving
- Separating out the DataImport feature into its own service and have a continuously poll the Cassandra instance OR use a Cassandra triggers
- Deployment, sharding, and horizontal scaling
- Exploring other search options and features of Solr
Ka Mok


